I will definitely think through & try to implement this stuff you’ve recommended to improve my methodology / process. Up until this thread, I had never even considered that maybe I could get significantly better across the board at calculations, but I think you’re right that it’s possible and desirable.
I’m also starting to think that maybe the subfield of physics I choose doesn’t matter very much, and that my focus for now should be more on how to get my error rate down.
Many process errors relate to process inconsistency. Some processes are like a flowchart where you follow the same steps every time. Some processes are more like having multiple flowcharts and having a random percentage chance to switch to another flowchart after each step. That means you can do the same problem (or type of problem) twice and get different results.
Inconsistency is OK when doing exploration or in other words when using creativity.
Inconsistency is bad when you already know what you want to do, and you don’t need to create any new knowledge, you just need to get a known job done. Math calculation is like this once you understand the problem and know how to solve it.
When errors seem kind of random, that shows some kind of inconsistency.
This comes up in other fields, e.g. on the TV show The Profit. It’s a reality TV show where the host helps struggling small businesses. One of his main helping tools is to make the business use a repeatable, consistent processes. How is a particular job done? Write it down, including details like relevant measurements. Then follow what you wrote down. Customers want consistent products. And having a clear, written process helps delegate stuff to employees or train new employees. And a clear process helps error correction – you can try to figure out which parts of the process is causing a problem and make a change. If you have an undocumented, inconsistent process then it’s hard to figure out what sporadic errors are coming from, and it’s hard to make a change to address them and test out that change. A good example of a process is a recipe for a restaurant. This might sound obvious, but he has gone and made businesses write down recipes with measurements of how much of each ingredient goes in each recipe, and then actually cook the dishes the same way every time – and this is a big improvement over restaurants that weren’t doing that! It also lets them more accurately calculate the cost of raw materials for each dish and price the dishes appropriately (sometimes businesses on the show are selling some products below the cost of materials). A lot of restaurants already understand this, but many don’t and are super disorganized! In math in general, standards and expectations for clear processes are lower than for cooking (although, for certain types of math, like doing proofs, standards are raised).
Similarly, some businesses on the show have cluttered, disorganized workspaces with no clean, smooth flow of work in process. Fixing that helps a lot. Some people have that problem when doing math, but you said you keep things pretty organized and non-messy, so maybe you’re OK on that issue.
That reminds me of the chess player Sam Shankland (roughly 30th best in the world) saying (source: my memory, and it’s somewhere on YouTube) that he thought he was good at chess calculation, but then he got a new trainer and a new more rigorous approach to calculation. He became much better at calculation – more able to accurately look ahead at a complex branching tree of chess moves (this is done mentally without moving chess pieces around or using any notes, books, scratch paper, writing, drawing, etc.). I don’t know the details of what he’s doing differently now though.
FYI, I asked that partly because I thought, after reading my explanation, you might agree.
There’s something interesting about this. Where does all the calculation work come from? Physics formulas tend to be elegant.
One issue is the formulas can be hard to calculate. There’s some sort of blocker. So you use numerical approximation methods. These methods can let you avoid doing something hard but replace it with a large amount of easier work. One way they can involve a lot of work is if you calculate a series of successively better approximations. Then instead of one calculation, you have to do one calculation per step in the series.
Another way to get a lot of work is guess and test methods. If you want an approximate answer for something, sometimes a good approach is to guess the answer and then check whether it’s close enough. You may need to check a large number of candidate answers before finding one that is precise enough. The reason this can work is basically that some math is much easier to calculate in one direction than the reverse direction. E.g. squaring is much easier than square rooting. By contrast, addition and subtraction are about equally difficult. It’s not immediately clear to me if division is significantly harder than multiplication or about the same difficulty.
There’s probably some deep/important/fundamental conceptual reason why math difficulty is sometimes (but not other times) asymmetric for an operation and its inverse, but I don’t know it offhand. I wonder if math people know this concept or didn’t think about it. There could be a connection to reversibility and irreversible proceses in physics.
This is actually an unusual mental model. Most people with process inconsistency do not conceptualize what they do anything like this. They would think of themselves as having zero flowcharts (and might even be confused by that, and say they don’t have any flowchart, or have no number of flowcharts, and find it weird that I attributed a number of flowcharts to them even if that number is zero). And they wouldn’t think of themselves as e.g. rolling dice to decide what to do. They aren’t like “OK, if I roll a 1 then I have to find flowchart 8 and go to step 34.” That is too much of an organized process like playing Dungeons & Dragons. What they do, or think of themselves as doing, is more arbitrary, subjective, whim-based, etc.
The model has some advantages though. It’s short. I thought lmf might understand it OK. And it’s more well-defined and clear than trying to say something like “people just kinda act inconsistently”.
Multiple flowcharts plus conditional transitions between flowcharts is actually powerful. You can model a ton of stuff with that. It’s actually kinda like programming. I thought lmf might already have some understanding of that.
Roughly, in programming terms:
flowchart = function
transition to another flowchart = conditional jump
branching within a flow chart = control flow statements like “if”
returning to a previous node on this flowchart = looping constructs or conditional jumps
And now if you imagine adding random conditional jumps into your codebase … lol, bad idea! Imagine you try to save a document, and the code does a few steps and then has a random chance to switch to printing instead of saving, and then after a few steps in the printing code it randomly jumps over to changing the font. Or if you want a closer analogy to what we were talking about, it could jump from saving your document as a pdf to a txt file, or jump from saving as the current version to a legacy file version (and if it goes back and forth between those a few times, you will get a broken file).
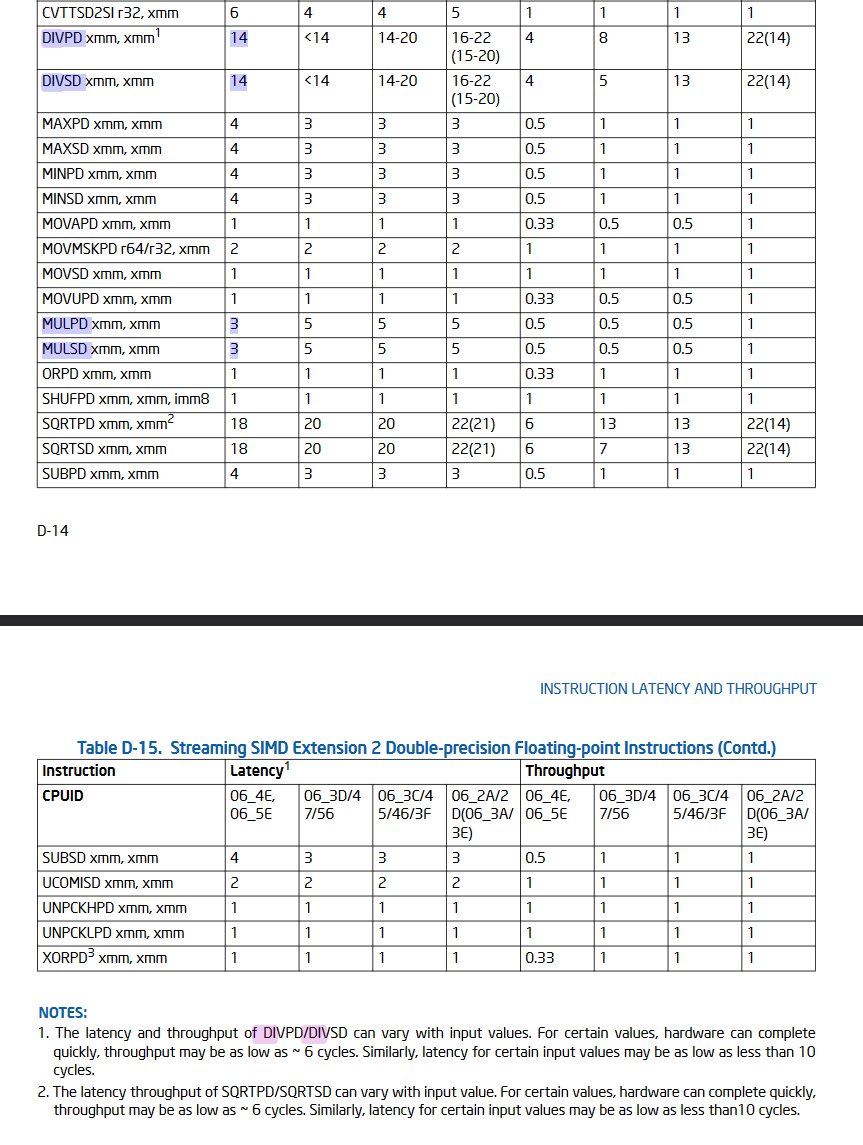
WRT division in chips/CPUs, it’s more expensive than multiplication, but addition/subtraction are comparable. Here’s some real numbers from an intel optimization guide (found via SO).
The DIV operations I highlighted below show: DIV operations take 14 cycles compared to 3 cycles for MUL (that’s latency), and you can start a DIV operation once every 4 cycles vs once every 0.5 cycles for MUL. There are lots of different optimization tricks so these numbers will be specific to the CPU design.
I suspect division being generally harder is related to why factorization is difficult. Not all division is hard, tho; it’s easy to divide by 10 using pen/paper, and lossy division by a power of 2 in binary is easy too (though you don’t get decimal places for free like you do with base10 and pen/paper). Dividing by -1 is also easy b/c it’s the same as multiplying by -1. There’s some symmetry at work there – in binary, dividing or multiplying by powers of 2 (with integer indicies) is just left and right shifting. So those mul/div operations correspond to something like adding or subtracting from an offset.
Also, division (and rooting) of integers map integers to the reals – so those are operations that won’t always work for purely integer systems. I’m not sure if there is a generic way to test if numbers evenly divide that’s cheaper than just doing the division.
It’s related to some areas of cryptography: factorization and discrete logarithm problem for asymmetric crypto, and hashing/trapdoor functions. I haven’t heard much about the why, though. Mostly it seems to be ‘we found a very asymmetric process, how can we use it?’ So they know about it at least. If you wanted to look into existing research, those areas might have some prior work.
That gives an answer about division but doesn’t explain why.
A reason I thought division and multiplication might be about the same is that one is repeated addition and the other is repeated subtraction. So if addition and subtraction are comparable, shouldn’t repeatedly doing them also be comparable?
I know there are different multiplication algorithms and some are faster than naive repeated addition. So maybe, in short, there is a shortcut for multiplication to make a more efficient algorithm, but there isn’t a shortcut (or it’s not as good) for division? That is, if you invert repeated addition you get something that’s about equally hard, but if you invert some other multiplication algorithm (that’s faster), you get something that’s harder.
If you take an algorithm for division, but invert it, I think one of the inputs (what used to be the remainder) will always be zero. If you have a data-structure like (numerator, divisor, answer), you can do repeated subtraction on the numerator and count up in the answer field: (11, 5, 0) → (6, 5, 1) → (1, 5, 2) (and then what used to be the numerator is the remainder). 11 = 5 \times 2 + 1. But if we invert it to get multiplication, there’s an extra input value (where the remainder went) that’s always 0.
This is not really a high overhead (it’s one extra addition), but it looks like it’s not as easy to invert a multiplication algorithm as it is to invert division, because multiplication requires fewer inputs than inverted division.
That’s my understanding, but I don’t know why there isn’t.
You’re right. I was annoyed that he said he didn’t understand something and then went on to write about it at great length instead of asking questions. I should have said directly that it’s better to ask questions about stuff you don’t understand rather than continue to write about it.
Methods designed for hardware implementation generally do not scale to integers with thousands or millions of decimal digits; these frequently occur, for example, in modular reductions in cryptography. For these large integers, more efficient division algorithms transform the problem to use a small number of multiplications, which can then be done using an asymptotically efficient multiplication algorithm such as […]. The result is that the computational complexity of the division is of the same order (up to a multiplicative constant) as that of the multiplication.
Neat about it changing with huge numbers. BTW the place I read about multiplication algorithms is Knuth, so that could be useful if you’re interested, but I don’t remember it well. https://www-cs-faculty.stanford.edu/~knuth/taocp.html (I don’t know if any new relevant ideas were created since he wrote.)
@lmf, why no discussion of and engagement with all that stuff @Elliot said to you? Stuff about process errors, process inconsistency, flowcharts, complexity management, etc.
You haven’t stuck your neck out on whether you think your post was aggressive or not. Your wording looks defensive and fence-sitting on purpose, similar to how many non-apologies apologies are written (e.g. “I’m sorry that you felt hurt by my actions.” or “I’m sorry that you interpreted what I said as an insult.”).
Do you think it matters much whether you were aggressive? Do you think being verbally, socially aggressive would be a big deal, an important problem?
Do you think your error was important? Why haven’t you attempted to figure out what caused it (or only done that privately without mentioning anything about your thoughts)? Is your plan to make no changes? It seems like the kind of issue that could happen again.
I expected that he should know better. I have reconsidered because asking questions and admitting ignorance are often treated as bad outside CF. So I have adjusted my expectations accordingly.
Yes, I completely agree with the paragraphs from ET that you quote. I shouldn’t expect to be fully aware of how my subconscious mind interprets aggression or social cues.
I’m not sure why I didn’t reply to it at the time.
My concern was not with your expectations. I was concerned with you getting annoyed and then treating someone in a socially negative way. I acknowledge the ambiguity, but that’s what I meant my questions to be about.