make an image of a full glass of wine. make sure it’s filled to the brim and even spilling over the edge a little bit. make the background white.
The AI then made its own prompt in turn:
“A full glass of red wine filled to the brim and slightly spilling over the edge, with droplets and a small trickle of wine running down the outside of the glass. The glass is a classic wine glass shape. Clean white background. Photorealistic, high quality, studio lighting.”
That was via gemini w/ nano banana, which I hope is the new one that released the other day (otherwise google what are you doing)
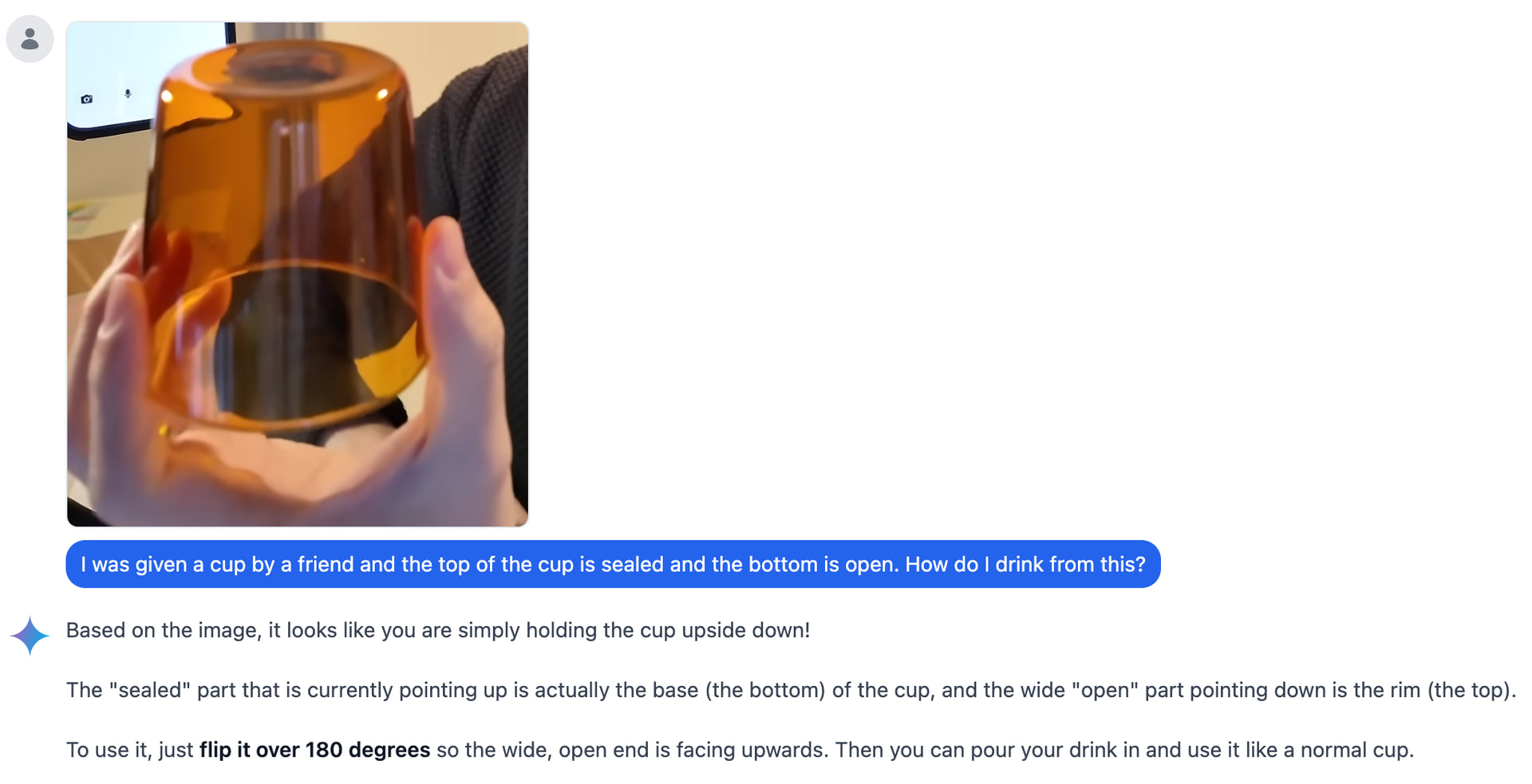
I think the wineglass is purely a training data issue though, so not really a good bellwether of anything.
One thing I was thinking the other day, though, is how it’s very confusing to talk about models or refer to them when they all have the same name / voice (from a provider). Like the chat gpt voices are the same I think for 4o and 5, even tho they had wildly different outputs. And the exact model matters, at least with code.
Prompt:
Generate image: a full glass of wine on a coffee table with a picture frame behind; in the picture frame it says “No, I hadn’t, but I expect it’s either fine or just a matter of time.”
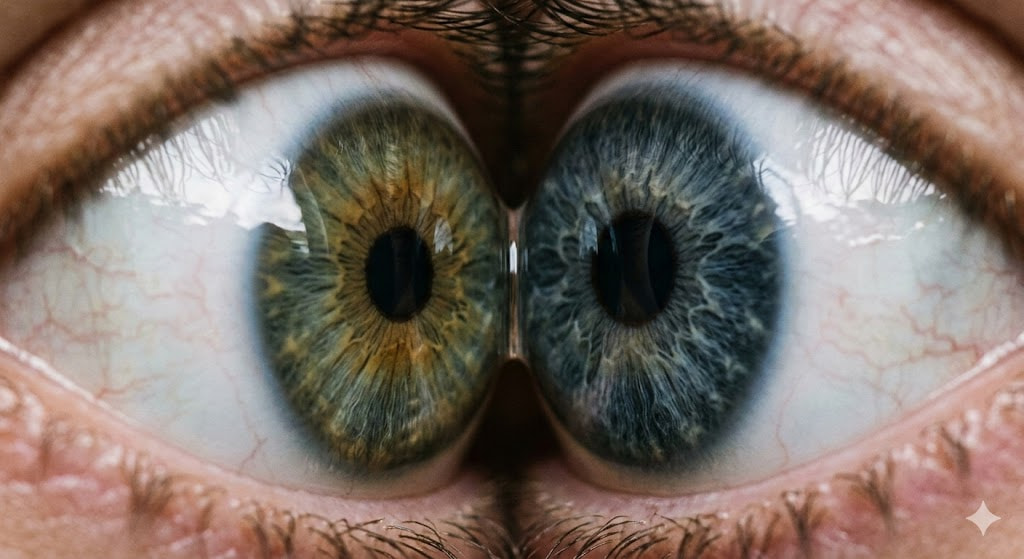
Thinking about it, ‘full glass of wine’ is ambiguous. Reading Jarrod’s prompt, I thought first maybe the overflowing description is going too far, but no it’s probably reasonable for this (and the point of the wineglass like 6mo ago was that image gen couldn’t do it no matter how hard you tried; two eyes touching eyeball to eyeball is another one that is hard to get)
Generate image: an overflowingly full glass of wine on a coffee table in a rustic countryside library with a picture frame behind; in the picture frame it says “No, I hadn’t, but I expect it’s either fine or just a matter of time.”
One of the problems with these tests being fixable by better training data is that when examples get popular they get put in the training set. The pelican on a bike svg example is one that seems to have lasted a while but they’re pretty good at that now too. Ball in a rotating hexagon similarly is basically retired at this point.
Some relevant new research about identifying and manipulating people-pleasing type behavior. The video and paper call them H-neurons (h for hallucination).
I don’t think this idea will solve all hallucinations but it seems to work well for some kinds at least. I’d guess hallucinations/biases that are baked into training data aren’t fixed by this (for that I think we’d need better ways of getting the models to like ‘think’ about implications of things and contradictions with other ideas).
Here’s a video about one of the testing methods, posing malformed questions, in more detail:
H-neurons might be responsible for the difference in performance of the models?
Anyways, it also makes the point that LLMs are worse for education than you would think, because when you don’t know about the topic your asking about it’s more likely that you subtly pose malformed questions. The best use case for LLMs is when you can check the answers it gives. I still don’t think AI works as a pure multiplier of your skill like he says in the video. I think it only sort of works like that.
I think the h-neurons idea kind of contradicts your earlier “don’t have conceptual understanding” point. What are concepts in this case? Maybe something like: an encapsulation of some idea and how it relates to other ideas. In that case, I’d say LLMs have conceptual understanding of many things (to some extent in some non-arbitrary way). They can be wrong, but people are often wrong, too.
Also some general follow up comments on h-neurons: I was actually surprised by the h-neuron thing, I thought more of hallucinations were baked into the model. Part of my reasoning for this is that figuring out what the truth is is hard. I remember wondering as a ~10 yo whether hobbits were real. I knew pygmies were real, so I figured hobbits could reasonably be real too. But elves aren’t real, and dwarves are kinda but different, and men are real. So it’s not immediately obvious that hobbits are fiction, IMO. That’s a bit of a trivial example, but I think people make the same kind of mistake (but more subtle) all the time and can’t tell if something is real or not. In fact, I think that’s essential for intelligence because you need to be able to consider that maybe things you believe are false, and consider new ideas as true while thinking through them. So I’d expect LLMs to be confident and wrong when people are confident and wrong, even when all evidence necessary to refute the idea is present. It would be pretty significant if some new AI method could actively reason during training or something to be significantly more opinionated (such that it’s compatible with reality).
Oh I meant to mention re h-neurons as well: although individual neurons were identified, most neurons are overloaded I think (meaning used for multiple things). There are way fewer neurons than parameters in models, so a 1T parameter model might have like ~100m neurons. I’m not sure that’s enough neurons to have like 1 concept per neuron or something.
I’m frustrated with all the real human beings I’m seeing going on camera reading undisclosed AI-written scripts. It’s screwing up the signal/noise ratio browsing the internet. Text-based AI use and videos with AI voices were already widespread, but I didn’t see a lot of humans reading AI scripts until recently.
In my experience this year, Claude is significantly better than Gemini or GPT (for coding and questions/chat. didn’t test some other stuff like image or movie generation).
Re coding: Did you try using gpt-5.4 and gpt-5.3-codex? IME they’re better than opus for some things. Opus is a lot more forgetful and does it’s own thing more. Practically speaking I think all three are good enough to vibe code 99% of projects. (Note: the code quality of all 3 is still below-par though.)