IDK if this is just me or how new this is.
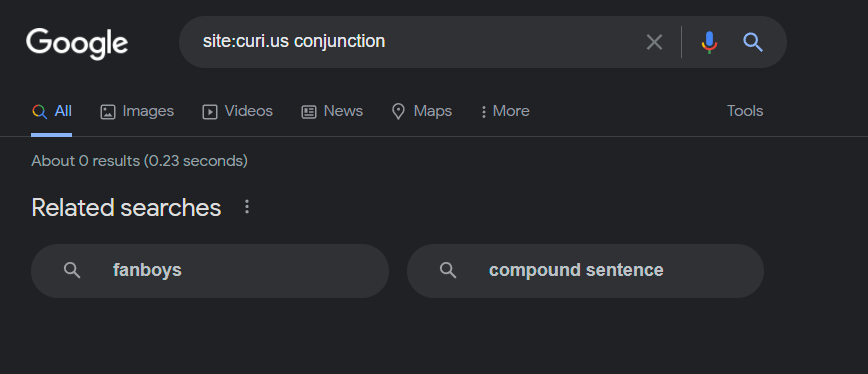
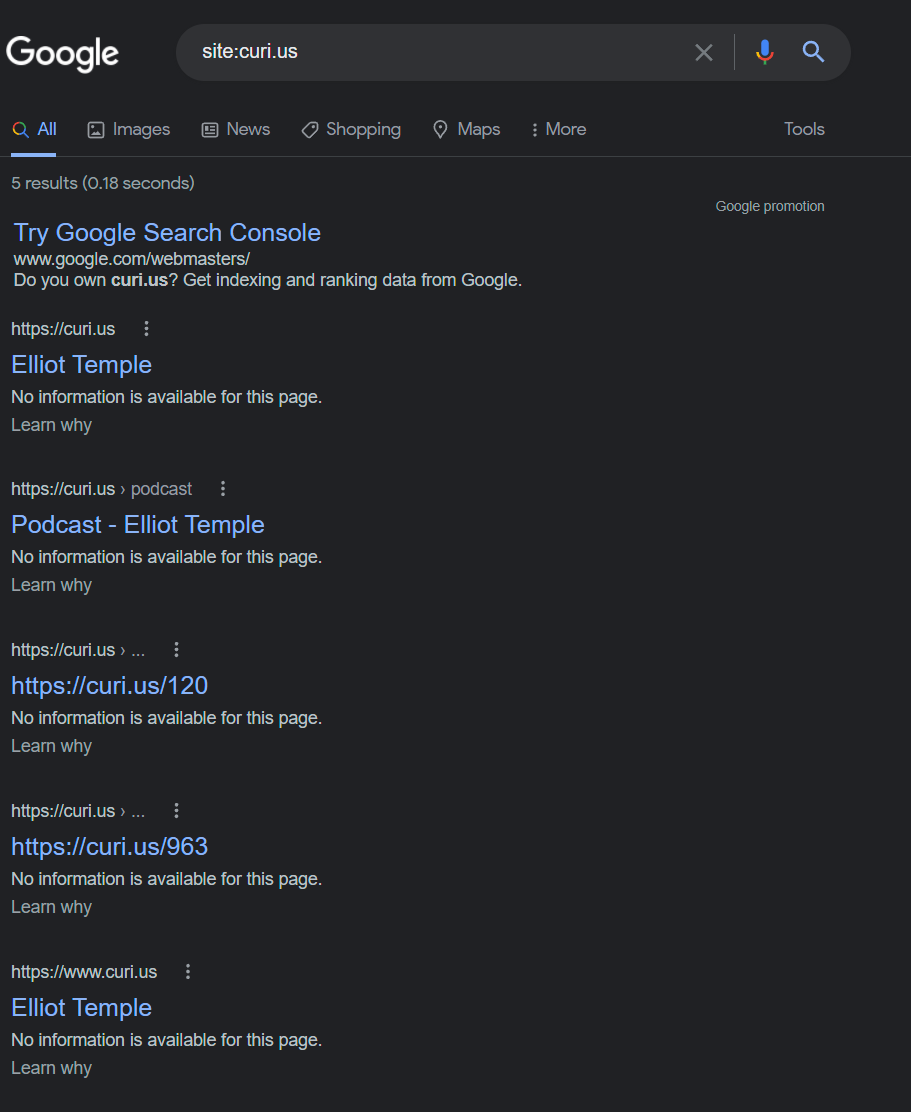
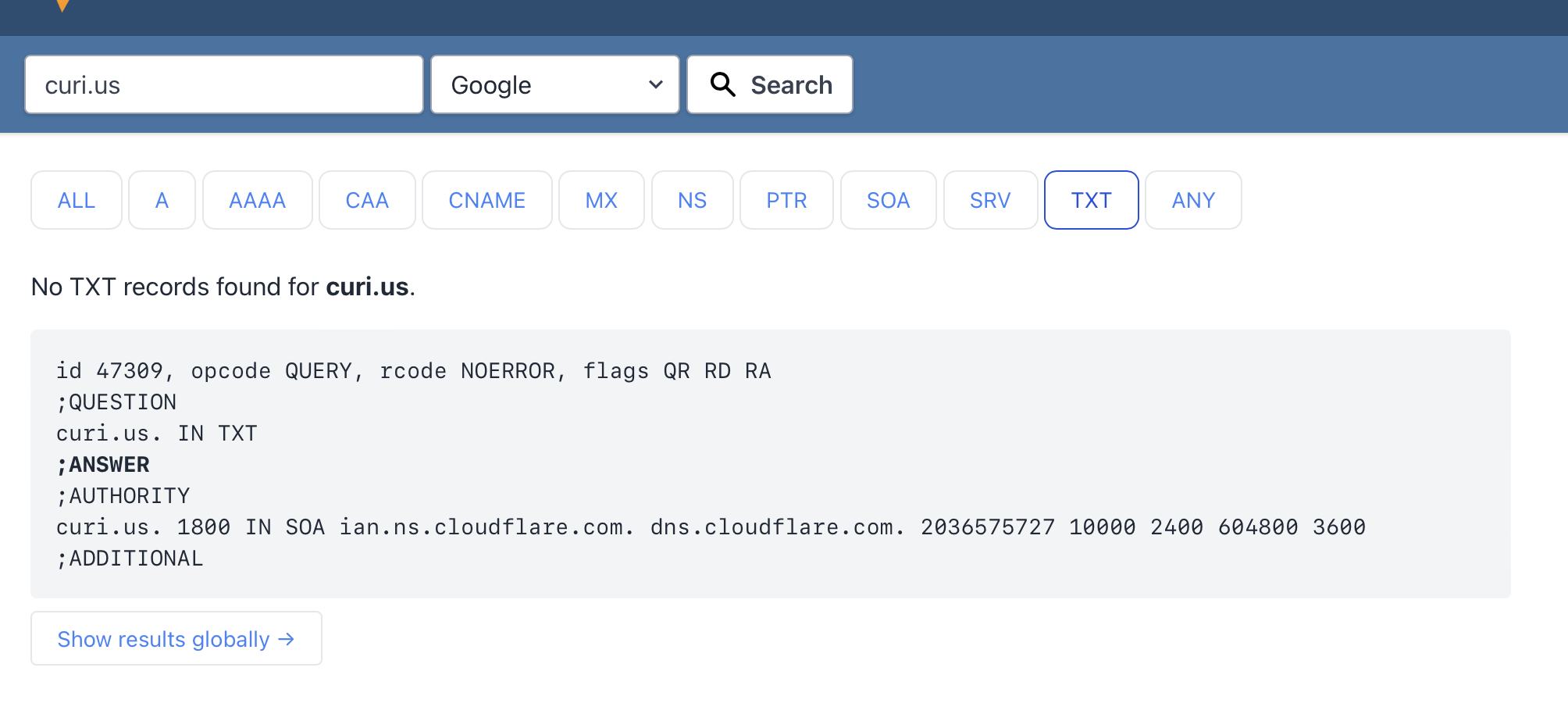
Searching site:curi.us conjunction in duckduckgo is fine, but on google I get literally nothing. (Same for www.curi.us)
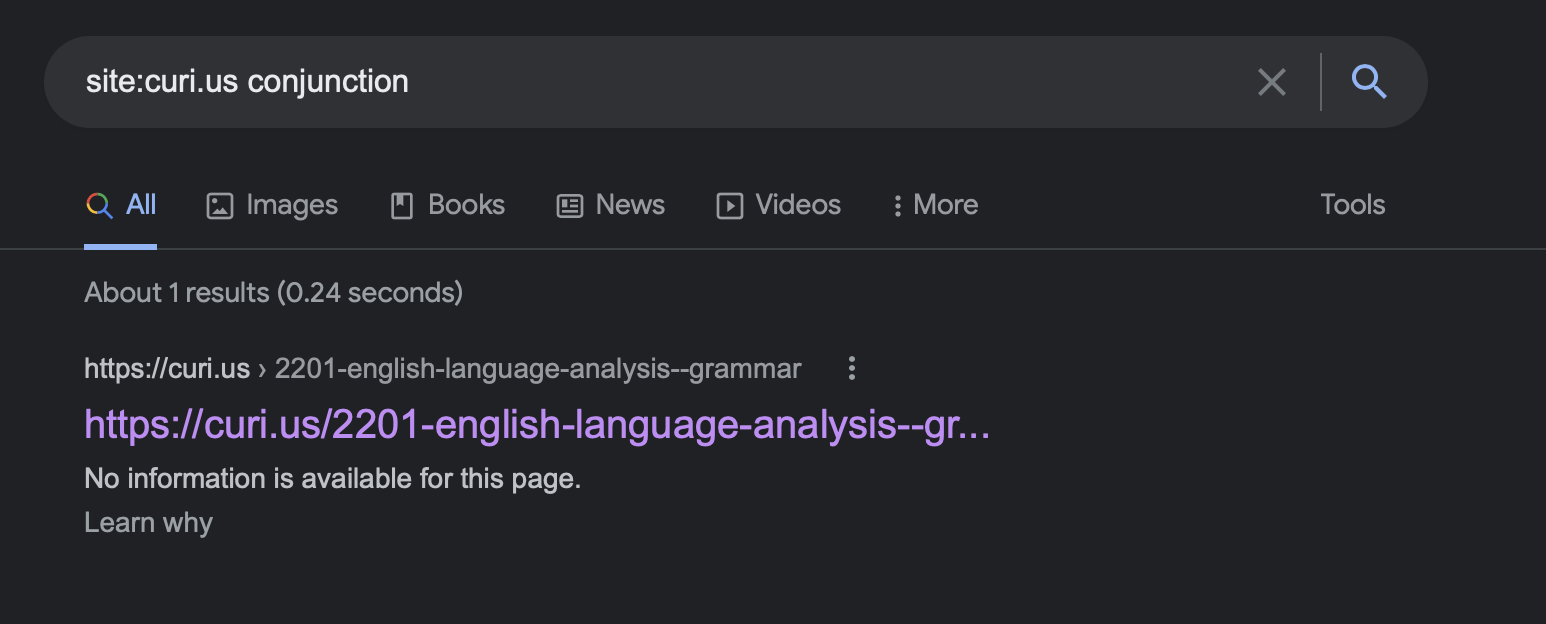
The link at the bottom to show omitted results makes more results come up. It works with a search for Rand too. I also do get one result for conjunction:
It shows 6290 impressions in the last year but only 55 in the last 3 months and 252 in the last 6 months, so it looks I’ve been blacklisted for at least 6 months. Actually it’s over a year but less severely initially because there are 30,000 impressions for the last 16 months.
Clicking around the Search Console I don’t see any errors or problems.
The Fallible Ideas site was also blacklisted/dranked/deboosted/something by Google between 12 and 16 months ago. There’s a huge drop in traffic when I compare those time periods.
My default search engine has been Duck Duck Go or Bing (varies by device) for more than 16 months. I highly recommend switching… I think it’s actually important to stop letting Google control the information you see by default. (It occurs to me that I still do use YouTube’s search feature. That seems problematic to rely on. I guess I should sometimes search for YouTube videos and channels with DDG or Bing.)
I used this a little recently b/c I realized stuff wasn’t getting indexed after updating my site.
One thing I found is that I had xk.io as a property and that this meant http://xk.io (not https). I also had a redirect from http to https. I think google was detecting this as a redirect error, but there wasn’t enough info to really investigate the problem much. Some pages that are only on the new site did show up (most of the old URLs are redirects to new pages but didn’t seem to have updated in google’s cache).
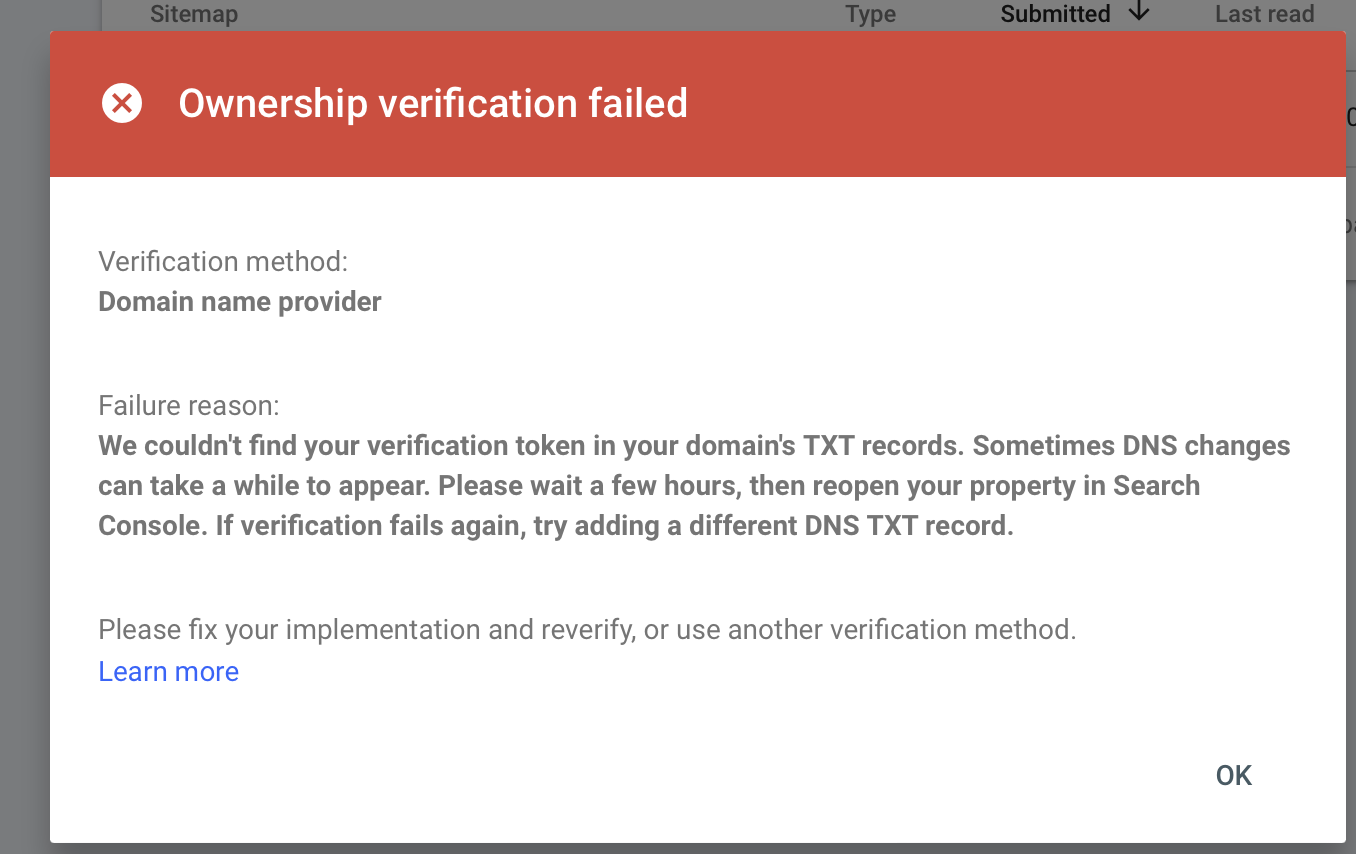
I solved the issue by deleting that existing property and creating a new property https://xk.io, and adding DNS validation (via TXT record). Then I submitted a page for indexing that wasn’t showing up and left it for a while.
Now lots of the new pages show up.
Maybe doing that could help?
There’s also a place to add a url for a sitemap that might help too (I don’t think I have one on xk.io)
Oh yes they are http entries in Google Search Console. I’ll try to fix that later, thanks. I already do have a sitemap for curi.us at https://curi.us/sitemap.txt and I entered it in Google Search Console ages ago. It appears to be missing the podcast pages and probably something else but all the blog posts look right.
FYI - I usually set TTL very low (60s is usually the lowest) when doing DNS stuff. That way it propagates v quickly. Afterwards you can set it higher if you want.
Try cloudflare – it looks like that’s what your NS servers are set to
No – it looked fine to me. (Maybe try a robots.txt validation tool? I don’t think that will help tho unless there’s like a syntax issue) I checked that the other day when I made the OP (and found the same BS claim from google, too).
That sort of claim (from google) feels like gaslighting. It wouldn’t be so bad if they gave webmasters decent reports or support, but it’s just a dead end.
Yeah, I wonder if there’s a rule like user agent lines only get reset after a list of disallows.
I found this suggestion from https://www.robotstxt.org/robotstxt.html
To allow a single robot
User-agent: Google
Disallow:
User-agent: *
Disallow: /
In any case, robots.txt seems like it probably has some complex rules to account for not having any delimiters between blocks/groups.
verified domains in google search console. it said to check back in a day for data. i’m not sure if it’s going to give me old data or not (maybe not due to no proof of ownership in the past).
looks like the FI site was not affected like the curi site:
I just made some tweaks to the FI site for mobile and added a viewport tag on curi.us but I’m not sure how to fix this in general on curi.us and get a good result given the two column layout. I don’t think putting the sidebar on top on mobile would work well since it’s tall. I could adjust the min width for the center column to be smaller but in my testing the results are less usable on my phone (larger min width means you get enough words per line instead of too few). Moving the sidebar to the right side and then making the main column width match the screen width for small screens might be better, but I don’t think google would like it: they’d say content width is larger than screen width. IMO mobile users should be prepared to scroll, zoom or user reader mode sometimes, and mobile browsers ought to be designed to work OK with regular websites (as I believe was the original goal) but now I think google wants you to make mobile more of a first class citizen that you design for and penalizes your search results if you don’t do that.
It’s all custom html/css design in a rails 2 app.
Suggestions for design concept or technical details?
Maybe you could move the sidebar stuff into a burger menu or something like that on mobile. But I think you should redesign what is available through the burger menu in that case as the sidebar has too many links for a burger menu in my opinion.
So maybe group the current links from the side menu more. Like in a “about” section, and “previous posts” section etc.
I made changes to https://curi.us for mobile. Please try it and let me know about problems. The goal is good enough, and to satisfy Google, not super nice.
It looks fine on my phone (and in the responsive-preview via browser dev console).
There were a few pages that scrolled horizontally – IDK how much of an issue google will think that is.
Google might also dislike some of the small links (like “Permalink | Messages” below posts on the home page) or how close they are together.
Actually, google has a page for testing this. Seems okay:
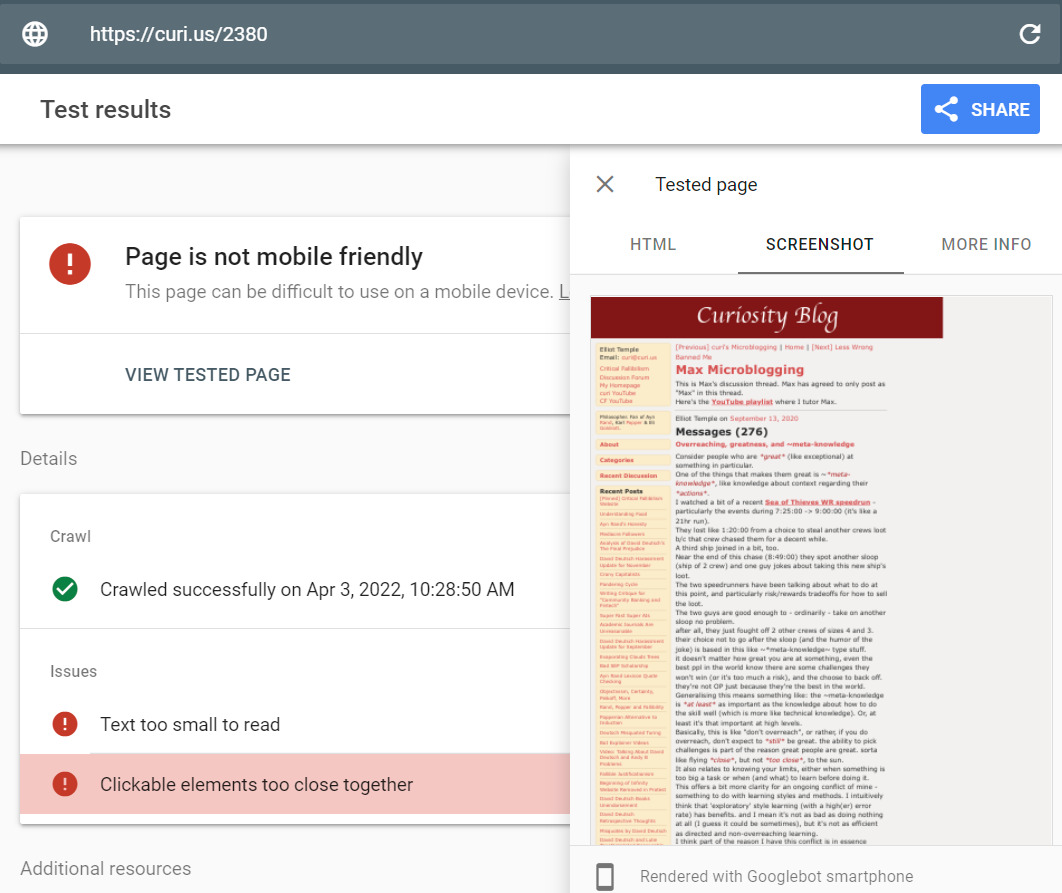
I don’t know why this would be, but https://curi.us/2380 (my microblog) showed up as not friendly – the screenshot shows that it’s the desktop version of the page though. If i go there on my phone it renders the mobile version. I didn’t test other posts via search console, but they looked okay from my phone.
i had a few weird results in my testing too. safari’s responsive design testing mode had some different behaviors than my phone.
that screenshot at the bottom just looks glitched. it has recent posts on the sidebar but with the blog post content apparently pushed below. that shouldn’t happen.
basically if the browser width is 640px or less, then the sidebar goes above the content instead of on the side, and also some of it is hidden, particularly the recent posts which would be way too tall to go there. sidebar no longer being a sidebar, and hiding part of it, have the same trigger condition.
i tried opening it in mac safari with both urls and making the browser narrow to trigger mobile mode. wasn’t able to get any glitches. edit: i tried the page in mac chrome, edge and firefox too. looked fine and properly transitioned to mobile layout when narrow.
good enough for now maybe. i set up bing webmaster tools (they let you import domains from google so you don’t have to verify each one). i think i’ll let both webmaster tools gather data for a while then go check what they’re saying in a couple weeks.