Kind of. Here’s how I’d explain it:
LLMs need an ‘alphabet’ to take in information. English isn’t very good because it has so few symbols, which are inefficient to run an LLM on. Instead, we could create an alphabet with like 200,000 characters which is much more efficient. Each one of those characters is a ‘token’. Practically, this (very roughly) equates to 4/3 tokens per word. Some words are one token, other words are made up of multiple tokens.
LLMs have something called a context window which is the most amount of information they can ‘see’ at once. You can’t fit more data in, but you can summarize data to ‘compress’ it. This context window is measured in tokens – the largest context windows today are about 1M tokens (so about 750k words). For comparison, all 3 LOTR books together are about 470k words.
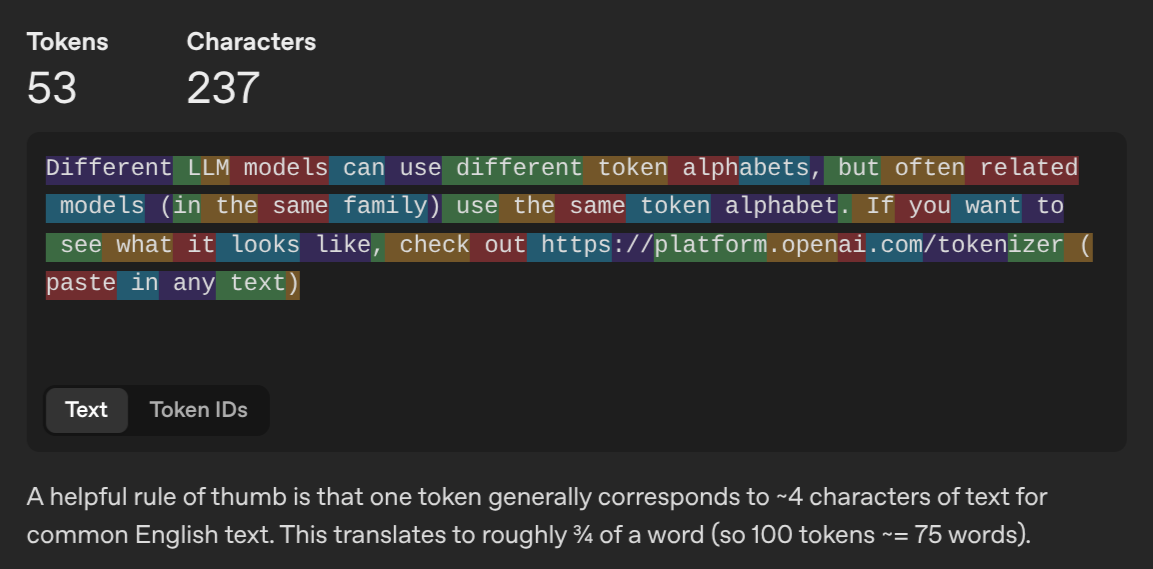
Different LLM models can use different token alphabets, but often related models (in the same family) use the same token alphabet. If you want to see what it looks like, check out https://platform.openai.com/tokenizer (paste in any text)
Yes, prompt(s) are what you send to LLMs. The prompt probably refers to the first message you send to an LLM most of the time.
Technically, each time you send a message to an LLM you are sending the entire chat history with your most recent message at the end. So in a sense you can think of the whole chat history as ‘the prompt’ that the AI completes.